Study of Sentiment Analysis using Twitter Data
By Alykhan Virani
What is Sentiment Analysis
Sentiment is the emotional tone or attitude conveyed by a text or other form of communication. It can be positive, negative, or neutral, and it reflects the speaker’s or writer’s feelings and opinions. Sentiment analysis is the process of automatically identifying and extracting sentiment from text or speech data using computational techniques. This can be used for a variety of purposes, including market research, customer feedback analysis, and social media monitoring.
Sentiment Analysis Techniques
Styx Intelligence recognises the significance of understanding customer sentiment towards their brand or product. That is why we use sentiment analysis to provide our customers with a comprehensive overview of their own customers’ voices. We can identify patterns and structures in social media and news media that reveal the emotional tone and attitude of customers and employees by analysing them. This enables our clients to make educated decisions about how to improve their products, services, or brand image.
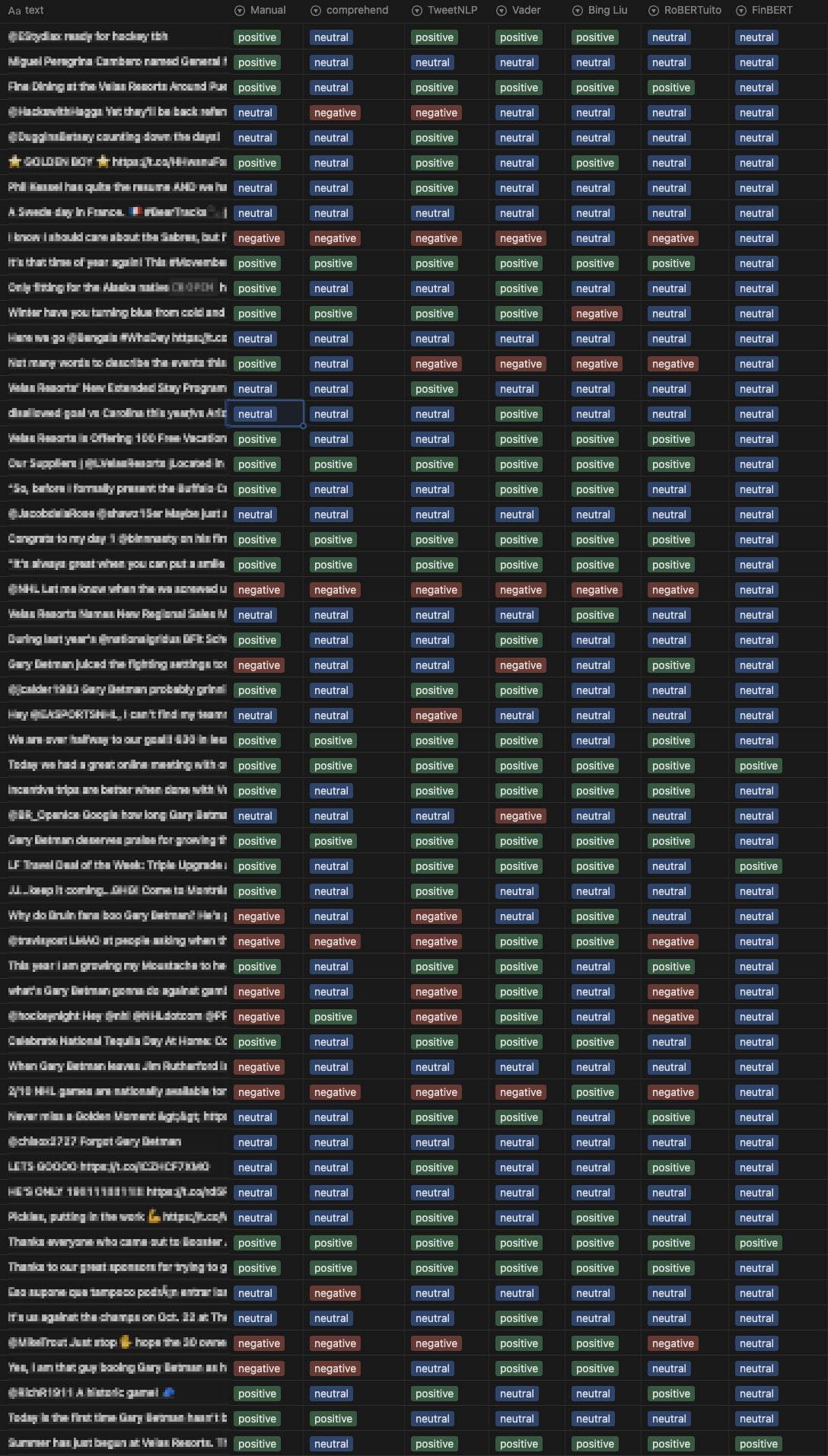
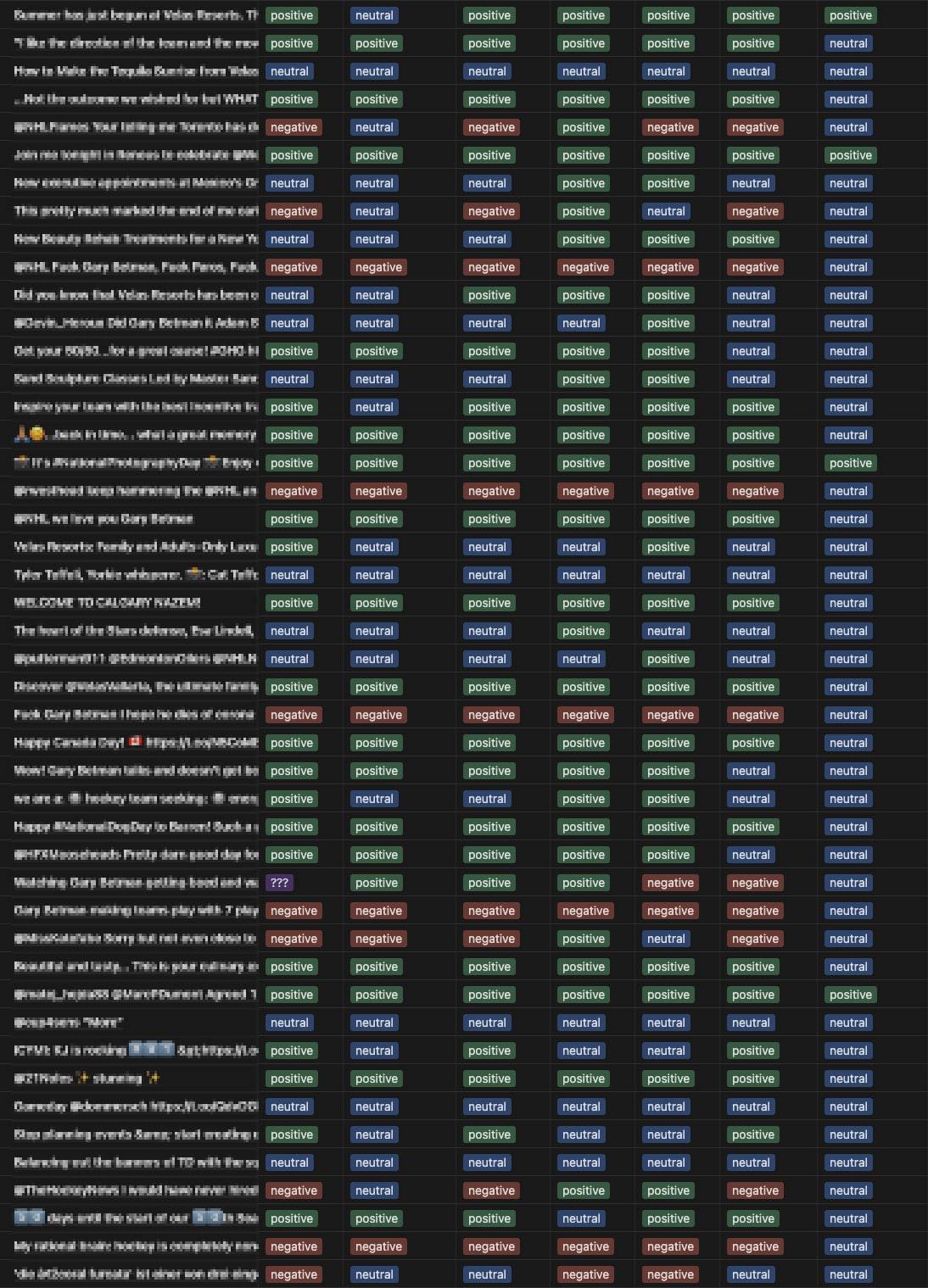
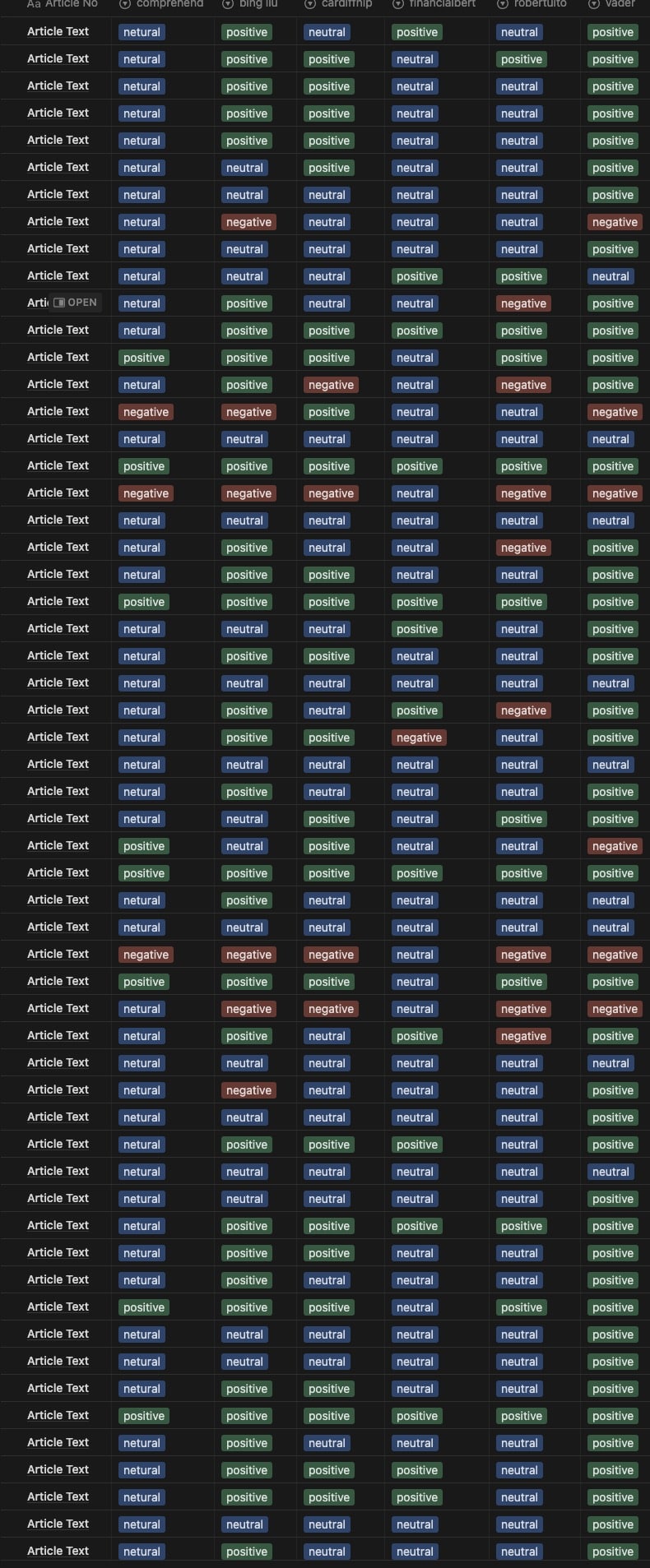
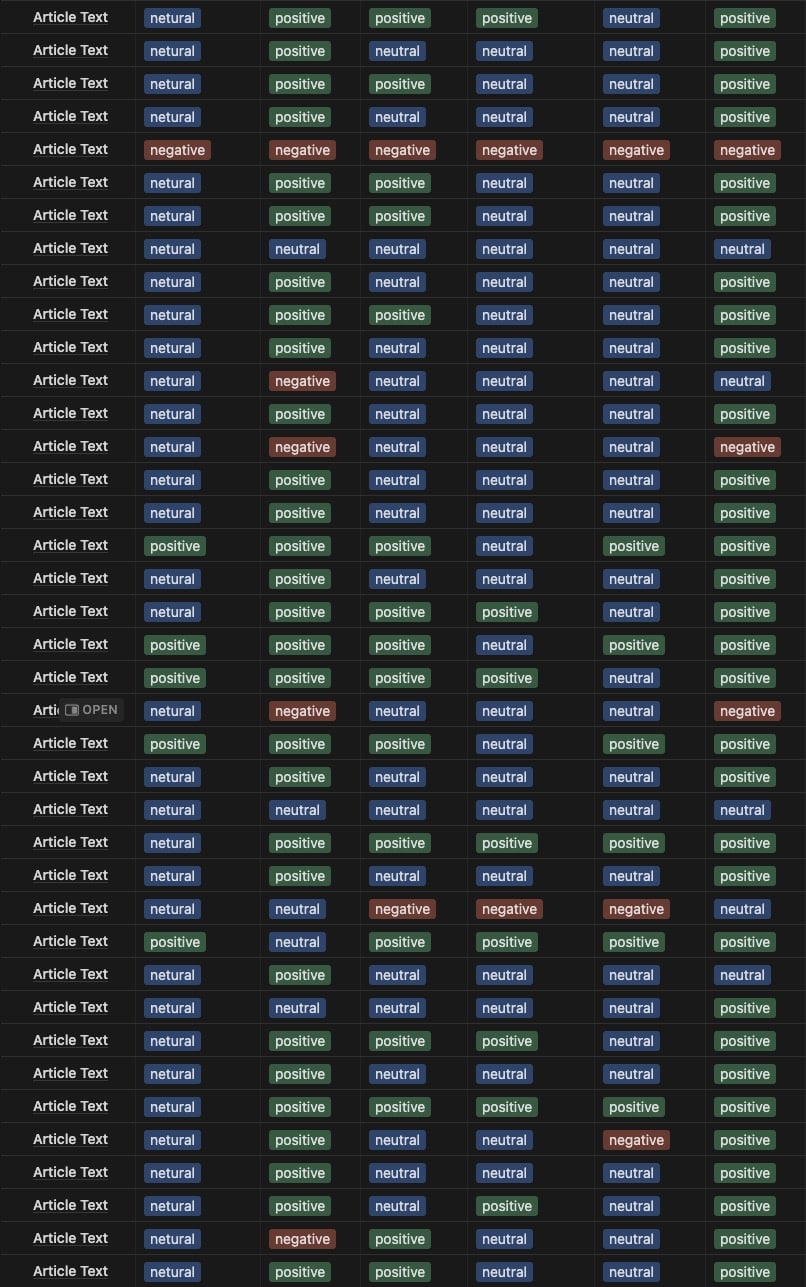
This paper examines the most popular sentiment analysis models currently available, as well as an analysis of a small dataset of Twitter tweets to determine how effective each model is at sentiment analysis. Each tweet was also checked by hand. A small dataset of newspaper and web articles was also used to test the models’ flexibility at small text samples and larger text documents.
To determine the most accurate sentiment analysis model available, our platform employs a combination of these models as well as some additional proprietary algorithms.
Sentiment Analysis Techniques Summary
| Method | Description | Key Features | Supervised / Unsupervised |
|---|---|---|---|
| Lexicon-based method | Matches words in the text to a pre-defined set of words in a sentiment lexicon and calculates the sentiment score based on the polarity of the matched words. | Simple and efficient; works well for basic sentiment analysis tasks. | Unsupervised |
| Machine learning | Uses machine learning algorithms, such as Naive Bayes, SVM, and Random Forest, to learn from labelled data and make predictions on new, unseen data. | Can handle more complex scenarios than the lexicon-based method but requires labelled data for training. | Supervised |
| Deep learning | Uses deep learning models, such as Convolutional Neural Networks (CNNs) and Recurrent Neural Networks (RNNs), to learn from labelled data and make predictions on new, unseen data. | Can handle more complex scenarios than the lexicon-based method and achieve high accuracy, but requires large amounts of labelled data for training. | Supervised |
| Rule-based systems | Uses a set of predefined rules to analyze the sentiment of a text based on linguistic and grammatical structures or on specific keywords and phrases. | Can be unsupervised, as the rules are designed based on domain knowledge and do not require labelled data. | Unsupervised (or partially supervised) |
Labeled Data
Machine learning, deep learning, and rule-based systems are more complex and use algorithms to learn from data and predict outcomes. These methods, which require a large amount of labeled data for training, can achieve greater accuracy and generalisation than the lexicon method. They can also handle more complex cases, such as sarcasm, irony, and figurative language, which a simple word-based approach may miss.
Labeled data is a dataset with labels indicating the desired output or outcome for each data point. Labeled data in the context of sentiment analysis would be a set of texts or documents that have been manually tagged with labels indicating the sentiment expressed in each text (e.g., positive, negative, or neutral).
Labeled data, in other words, serves as a foundation for a machine learning model to learn from. The model can learn to recognise patterns in data that are associated with specific labels by feeding it a set of labelled data. The model can then use these patterns to forecast the sentiment of new, previously unknown data.
Labeled data is typically created by people who are knowledgeable about the task at hand, and it can be time-consuming and expensive to create. It is, however, required for supervised machine learning approaches, in which the model is trained on labeled data before making predictions about new, unlabeled data.
Unsupervised machine learning approaches can still be used in the absence of labeled data, but they rely on the model to identify patterns and relationships within the data without any preconceived notion of the desired output.
Here’s an example of labeled data:
Assume we have a dataset of product customer reviews and want to train a machine learning model to predict whether each review is positive, negative, or neutral. We’ll need a labelled dataset with each review labelled with its corresponding sentiment to do this.
Here’s an example of what that labeled dataset might look like:
| Review Text | Sentiment Label |
|---|---|
| This product is amazing! I love it so much. | Positive |
| I was really disappointed with this product. | Negative |
| The product is just okay. It does the job, but not great. | Neutral |
| This is the best product I’ve ever purchased! | Positive |
| I don’t recommend this product. It’s a waste of money. | Negative |
| The product exceeded my expectations. I’m very happy with it. | Positive |
In this example, each review in the dataset is labeled with its corresponding sentiment label, which is either positive, negative, or neutral. This labeled dataset can then be used to train a machine learning model to predict the sentiment of new, unseen reviews.
This introduces a new term of supervised vs. unsupervised methods
Supervised vs. Unsupervised Learning methods
Supervised Learning Method
Supervised learning methods necessitate a labeled dataset, in which each text has already been annotated with its sentiment. This category includes machine learning and deep learning methods, in which the algorithm is trained on a labeled dataset and learns to make predictions based on the patterns it observes in the data. The model is trained on a set of inputs (e.g., text) and corresponding outputs (e.g., positive/negative/neutral sentiment labels) in supervised learning. Once trained, the model can make predictions on previously unseen inputs.
Unsupervised Learning Method
However, unsupervised learning methods do not require labeled data. This category includes rule-based systems, in which the rules are designed based on domain knowledge of the problem and do not require labeled data. Unsupervised learning involves training the model solely on a set of inputs (e.g., text) with no corresponding outputs (e.g., sentiment labels). The goal is frequently to find patterns or structure in data that can be used to infer the sentiment of the input text.
Unsupervised sentiment analysis models rely on carefully curated knowledge bases, lexicons, and databases that contain detailed information about subjective words and phrases such as sentiment, mood, polarity, objectivity, subjectivity, and so on.
It’s also worth noting that some approaches may combine supervised and unsupervised methods. Unsupervised approaches, for example, may be used to identify patterns in data, which are then used to design a supervised learning algorithm that is trained on labeled data.
| Feature | Supervised Sentiment Analysis | Unsupervised Sentiment Analysis |
|---|---|---|
| Training data | Requires labeled data | Does not require labeled data |
| Training process | Uses labeled data to learn patterns in text | Identifies patterns in text without preconceived notion of sentiments |
| Accuracy | Can be more accurate | May be less accurate |
| Resource requirements | Requires a significant amount of labeled data and resources to train the model | Requires fewer resources to implement |
| Applicability | Useful for large-scale sentiment analysis and specific sentiment classification tasks | Useful for exploratory analysis, identifying sentiment patterns, and when labeled data is not available |
Sentiment Analysis
For this exercise we primarily focused on Twitter data and used the most popular sentiment analysis models currently available.
- Bing Liu’s Lexicon
- NLRoBERTuito
- FinBERT
- CardiffNLP/TweetNLP
- Vader Lexicon
- AWS Comprehend
Bng Liu's Lexicon
The Bing Liu’s Lexicon is an exhaustive compilation of both positive and negative sentiment terms in the English language. With the publication of the original paper by Hu and Liu in KDD-2004, it has been compiled and developed over the course of a number of years, and it currently comprises somewhere in the neighbourhood of 6800 words. The lexicon was developed specifically for the purpose of doing sentiment analysis, with the intention that each word in the list would be categorised as having either a good or negative sentiment associated with it. Words like as “love,” “happy,” “sad,” and “anger,” for instance, can be utilised effectively in order to ascertain the underlying tone of a piece of written communication. In addition, the lexicon can be utilised to determine context-dependent sentiment terms, which can then be utilised in the analysis of comparative sentences to determine the overall sentiment of the sentences.
The lexicon can also be utilised for a variety of other purposes, such as the identification of emotions. For example, one can use the lexicon to determine the feelings that are conveyed in a piece of writing, such as happiness, sadness, wrath, and fear. Also, it can be utilised in the detection of contextual sentiment terms, which can assist in contributing to the improvement of the accuracy of sentiment analysis. Last but not least, new terms are consistently added to the lexicon as part of an ongoing process, which makes it possible to conduct more precise sentiment analysis.
NLRoBERTa Model
NLRoBERTa is a large pre-trained language model that is a member of the family of RoBERTa models. These models are based on the transformer architecture and belong to the RoBERTa family. A group of researchers from the University of Washington and Facebook AI collaborated on the development of this system.
NLRoBERTa is an abbreviation that stands for “Noisy Student RoBERTa,” and it was trained by employing a variety of self-supervised learning strategies in conjunction with data augmentation. The phrase “noisy student” refers to the fact that the model was trained using a teacher-student training approach. In this method, the teacher model is trained on a significant amount of data, and the student model is trained on the same data as the teacher model, but with noise and augmentations added to it. The “noisy student” portion of the name refers to the fact that the model was trained using this method.
VADER Lexicon
VADER (Valence Aware Dictionary and sEntiment Reasoner) is a lexicon that is commonly used in natural language processing for sentiment analysis. The VADER lexicon was created specifically to analyse social media text, which frequently contains slang, emoticons, and other types of informal language.
Over 7,500 lexical features, including words, phrases, and even punctuation marks, are included in the VADER lexicon. VADER also considers grammatical and syntactical structures commonly used to convey emotion, such as negations, intensifiers, and emoticons.
CardiffNLP/TweetNLP
CardiffNLP/TweetNLP is a pre-trained machine learning model for Twitter sentiment analysis. It was created by Cardiff University’s School of Computer Science and Informatics researchers and is freely available on GitHub.
The model is built with a mix of deep learning techniques such as convolutional neural networks (CNNs) and long short-term memory (LSTM) networks. It was trained on a large dataset of tweets labelled with positive, negative, or neutral sentiment.
One of the CardiffNLP/TweetNLP model’s key strengths is its ability to handle the challenges of analysing sentiment in Twitter data. Twitter messages are frequently short, filled with slang, abbreviations, and emoticons, and can be highly context-dependent, making sentiment analysis more difficult. The model, on the other hand, is intended to capture the nuances of Twitter language and to accurately predict sentiment in Twitter data.
The CardiffNLP/TweetNLP model has been demonstrated to perform well in a wide range of sentiment analysis tasks, including sentiment analysis of tweets about politics, healthcare, and social issues. It has also been used in research studies on cyberbullying, hate speech online, and mental health.
Overall, the CardiffNLP/TweetNLP model is a useful tool for sentiment analysis of Twitter data, and it can provide valuable insights into Twitter users’ sentiments and opinions on a variety of topics.
FinBert
FinBERT is a pre-trained deep learning model for financial sentiment analysis that data scientists can use to examine financial news and social media data. The model is built on the BERT (Bidirectional Encoder Representations from Transformers) architecture, which is a well-known pre-trained language model that has been demonstrated to be effective for a variety of NLP tasks.
This comprises news stories, firm reports, and other forms of financial records. It has also been taught to understand financial jargon and phrases, such as “profits per share” and “stock price,” which are essential for financial sentiment research.
In this study, we selected FinBert to determine the effect of a special model on tweets unrelated to financial services.
AWS Comprehend
AWS Comprehend’s sentiment analysis model is a drop in solution that provides a host of machine learning services including sentiment analysis. AWS Comprehend supports multiple languages, including English, Spanish, French, German, Italian, Portuguese, and Japanese.